corpora.ai: Striving for one experience
For Corpora.ai to satisfy the numerous research hypotheses it receives, there are numerous sub-systems that operate independently to handle the web of sub-requests

All developers, no matter experience or specialism, share a desire for their products to have international reach. We too, possess the same desire. This article details our approach and the result of our work focusing on internationalization support.
For corpora.ai to satisfy the numerous research hypotheses it receives, there are numerous sub-systems that operate independently to handle the web of sub-requests - none of which are scraping/crawling requests. Whilst this affords users the greatest possible research experience, being able to generate detailed contextual multi-page reports, it presents unique challenges for internationalization. These challenges affect the intricate routines within each sub-system as well as storage and presentation of the resulting content.
To better understand our approach, we need to talk about the approach of the separate groups our sub-systems and applications reside.
-
Back-End: This includes the DB and Patented systems that satisfy requests
-
Front-End : This is the application users interact with
The Back-End: A Summary
As an initial approach, the DB and sub-systems all accept multi-language input, and prioritize native language content from the corpus. The resulting set of source content is then enriched by content that is found within the bulk corpus by use of an English query (the international language has the majority of content and has mappings to other non-native language content). Our bespoke main engine powering corpora.ai uses a distinct approach to find matching content which will be covered in another article due to its complexity.
All content is ingested and processed in their source languages, and then is written out in the source query language. This approach ensures that the research content has all the possible accurate content it can to provide the attributed summaries that constitute the document content.
With Back-End approach only, we can satisfy queries written in a variety of languages, whilst the application itself remains English only. And with this, we end up with an experience for the user as shown below:
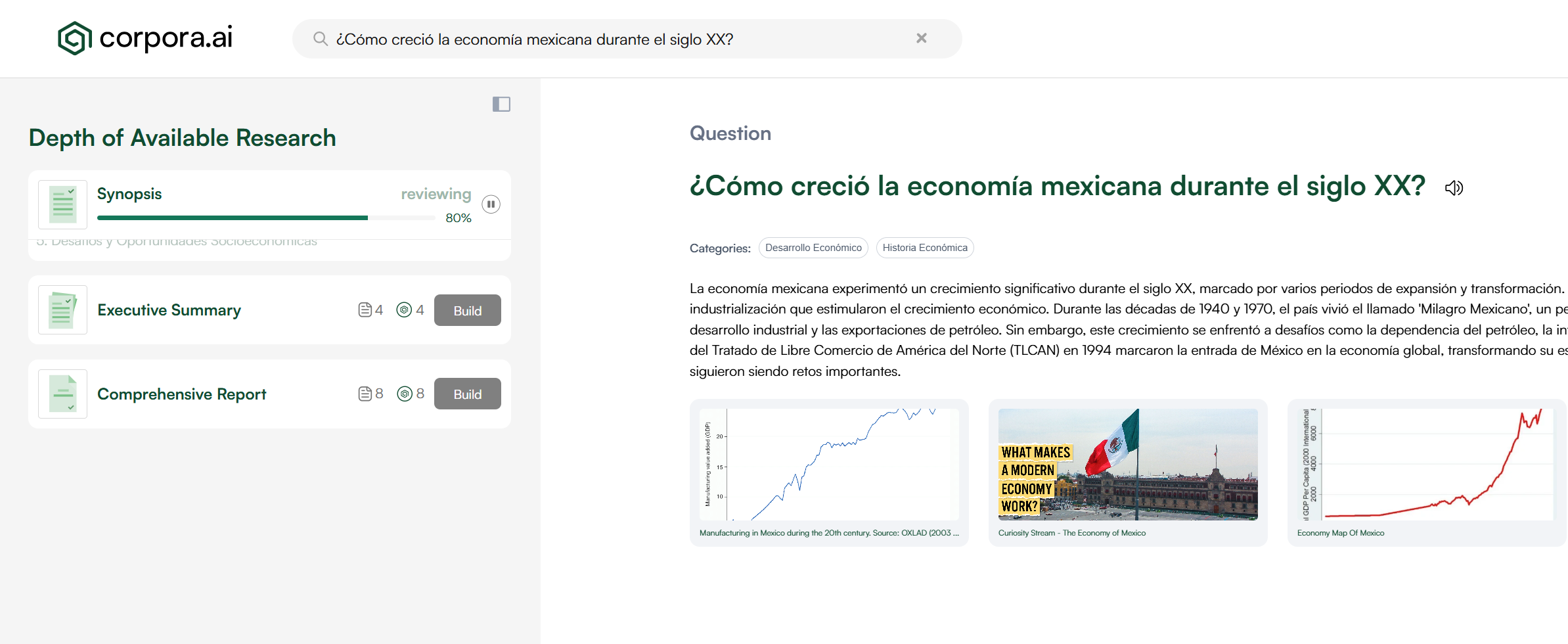

Examples of the Back-End only internationalization
As is shown above, the Back-End internationalization is pivotal for the content authorship piece. Without it, the content would perpetually be authored in English and as a product, we would have to rely on browser based or external translation services to translate the research reports to the users desired language.
The Front-End: A Well Trodden Path
There exists numerous libraries for Front-End applications that manage internationalization. We have used a market-leading library to simply manage the selection of the language ourselves, and rely on a custom translation piece that has proven to be cost-effective and reliable. In terms of layout, this has been handled primarily by browsers through best-practises.
This made the process wholly achievable, reliable and simple resulting in the Front-End internationalization taking less than a handful of days to complete!
Below shows both the Back-End and Front-end internationalization working together to provide the best possible native experience.
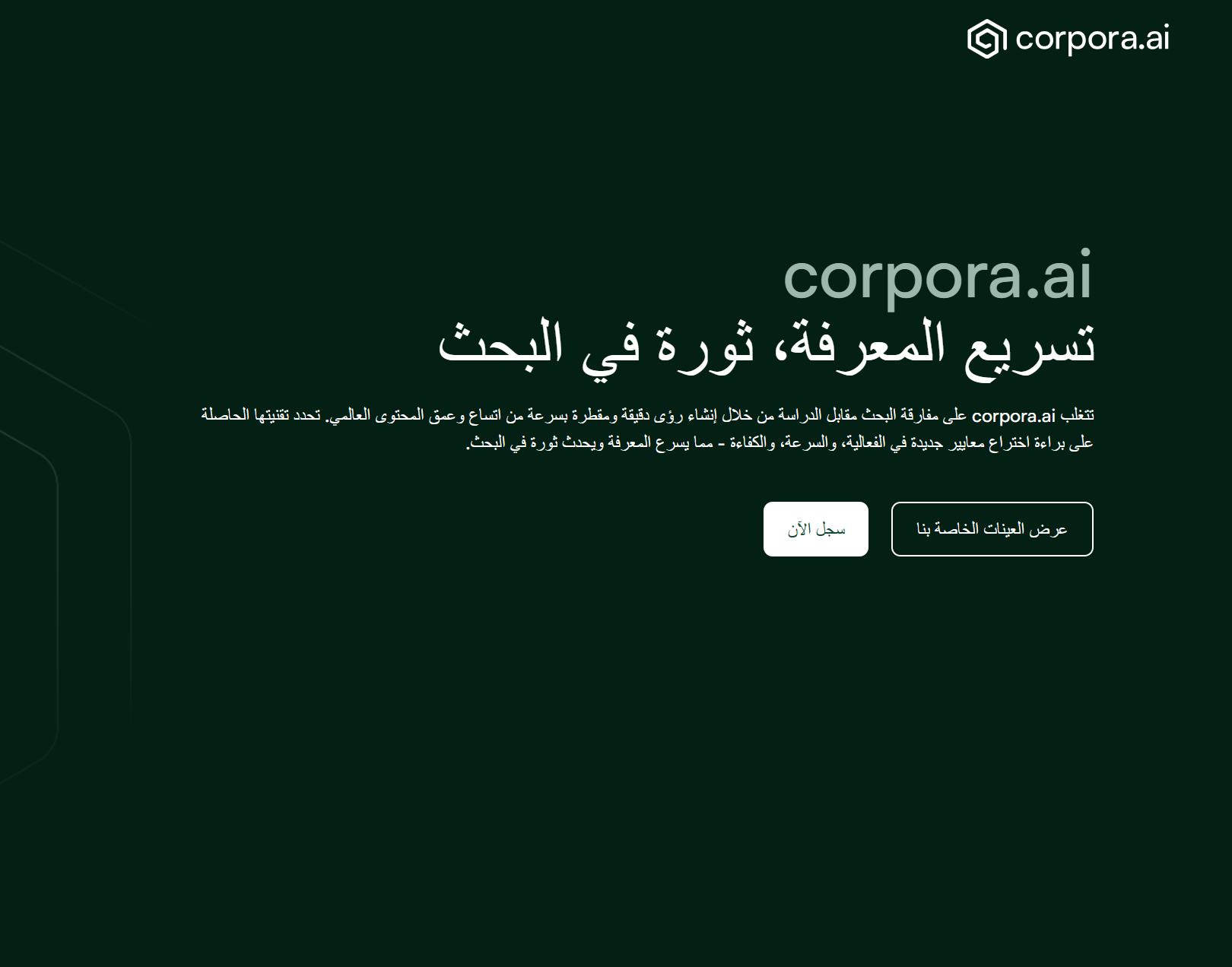
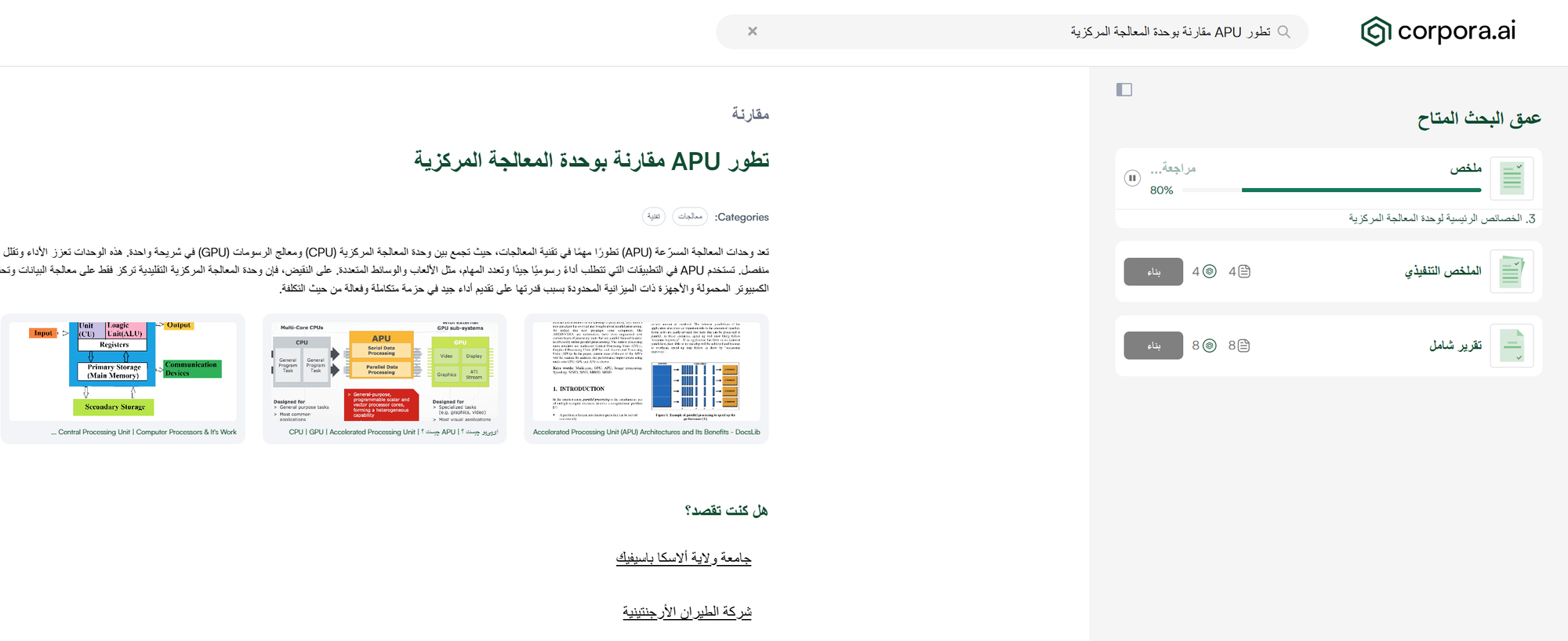

The screenshots shown above show how the Front-End and Back-End have progressed in a very short amount of time to support native experiences across locales.
We as a team continue to grow and evolve, just as our product and applications do. We will always be looking for improved user experiences and use cases. To alert us to issues regarding internationalization or any other issues, either comment below or email us at support@corpora.ai


Comments ()