corpora.ai: System Flex
As we are now in public beta, we decided to try stretch the legs of corpora.ai as a complete system.

SERP Listings, Report Generation and Load Balancing
As we are now in public beta, we decided to try stretch the legs of corpora.ai as a total system. And as is usual with our team, we thought about stones and birds, thus arriving at the decision to expose corpora.ai to the wider world through a process of sitemap submission and syndicated triggers to generate research reports. This article serves as an overview of said process.
As all of our preceding blog content illustrates, we are a Research Engine not a Search Engine, so why would we want to be listed in SERPs (Search Engine Result Pages)? The majority of web users are not researching, they are ultimately using Search Engines as expected to find content based on their query for single threaded consumption i.e. to read; to watch; to listen; to buy; etc. But a large portion of web users are looking for answers and understanding. We believe our smallest research report satisfies their intent better than SERPs do, as you gain full information in a readable form, with quick access to the source content (attribution links).
The other benefit of this approach is usage. The more use the application receives from the more varied of users, the greater the final product will be. And for all of us at corpora.ai, the ideal is a platform that can dynamically cater to user research in as many forms as possible, and we are only at the start of the journey.
To answer the question of how we are generating these SERPs, we have a reactive, lightweight and efficient system of producing research reports that are highly topical and informative. To explain this process at a high level, we consume a series of feeds of news, investigative and blog content within each sources respective terms, from each content piece we generate a hypothesis and then trigger the creation of a research report with that hypothesis. This final step touches the entirety of the core systems and is no trivial piece.
From hypothesis to fully attributed and generated research report, takes under 60 seconds. For the article above, the following infographic is shown at the bottom to depict the distillation of information, which highlights the value being extracted in such a short amount of time from our bespoke AI Research Engine.
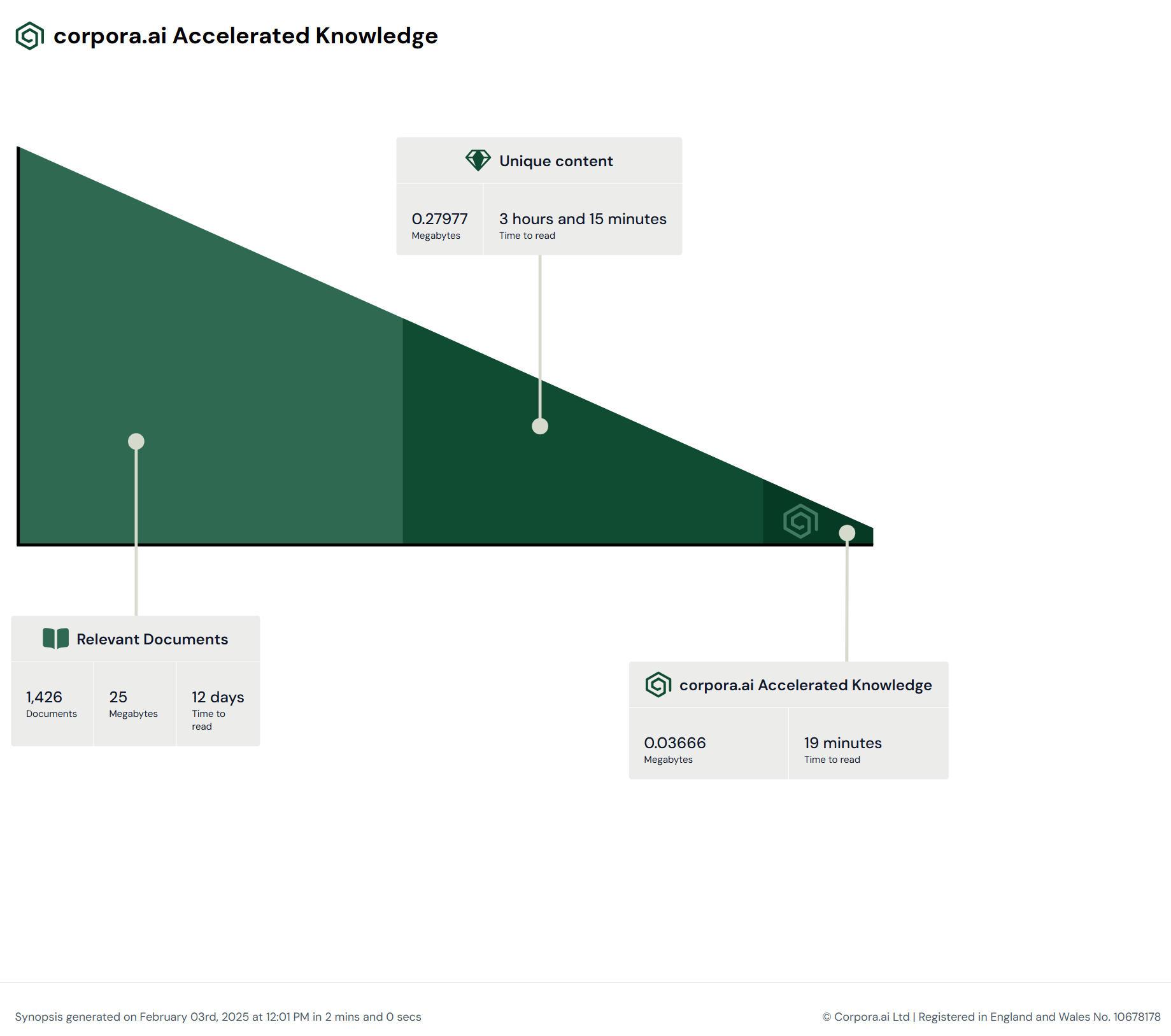
Our proprietary temporal graph store is the linchpin of corpora.ai, and as research requires a panoptic understanding of the higher and lower scales of the topic, as well as everything in between, corpora.ai is only viable using our graph store. Our store is also real-time, consuming data and events as they are created/happen. This is vital for research, as researchers are never at a disadvantage due to the update cycle of alternative systems when using corpora.ai.
The efficiency of our system is only possible due to the patented technology that provides Petabytes of proprietarily compressed, stored and analyzed content, which allows us great flexibility in our hosting approach to handle load. in handling load, we follow industry standards possessing a hybrid footprint and leveraging a mixture of CDN distributed content and load balanced servers to satisfy user load.
So far, we haven't seen any spike in usage on the individual servers, or in the consumption of CDN content. We will be continuing to monitor this and improve our footprint throughout our public beta.
We welcome all feedback via any of the following channels:
- Email: support@corpora.ai
- X: https://x.com/corpora_ai
- Facebook: https://www.facebook.com/61567821315594/
- LinkedIn: https://www.linkedin.com/company/corpora-ai
- Product Hunt: https://www.producthunt.com/posts/corpora-ai


Comments ()